🚧 These docs are still under construction. Reach out on Discord if you’d like more information on anything about Agent Cloud.
Our platform integrates with hundreds of providers, see all our possible integrations or contact us to suggest integration with a new one.
Datasource Form
Allowing for many different connections means manny different ways of connecting to providers. Each one can’t be covered here but the Airbyte Docs provide an ability to search for any connector, take a look at it’s docs and see what’s required to connect Agent Cloud to your data provider.Example Finding Form Values
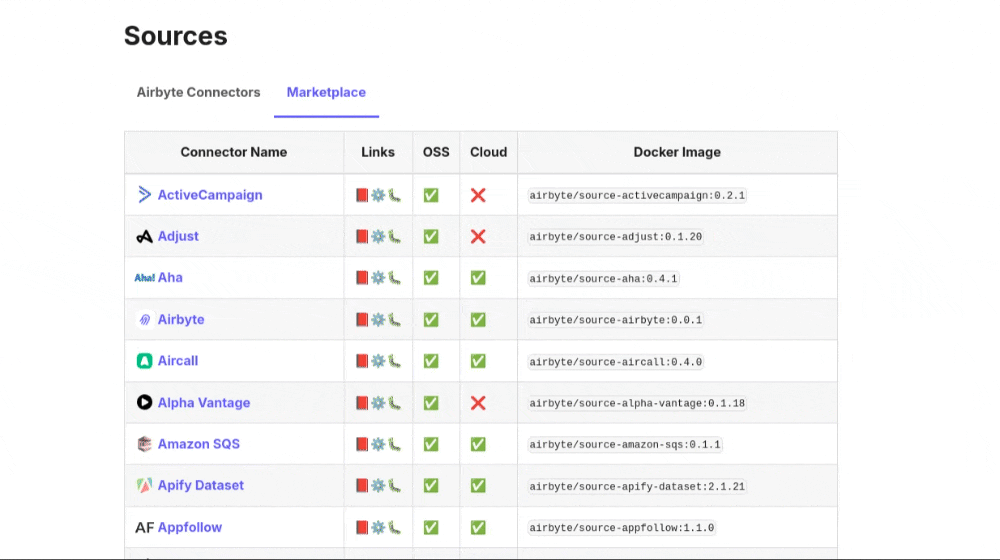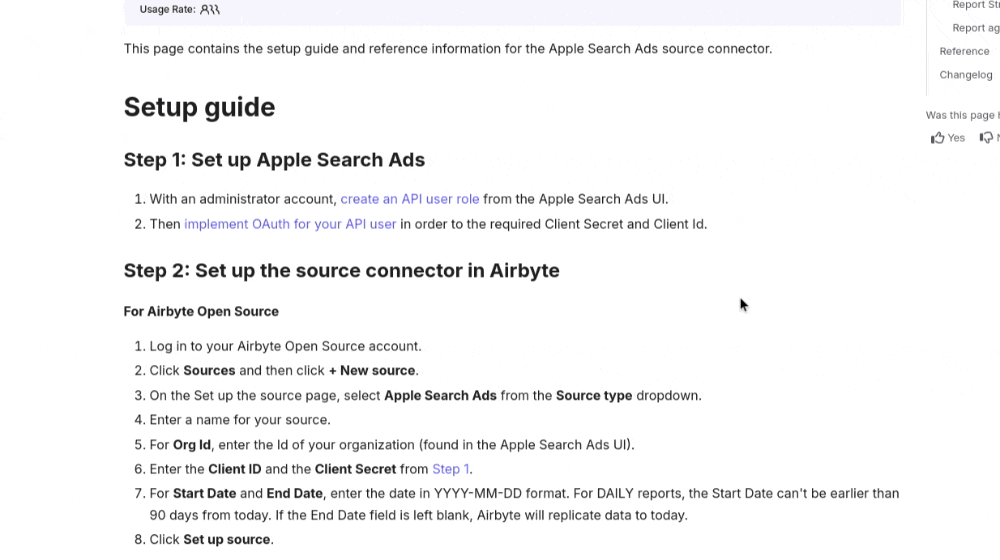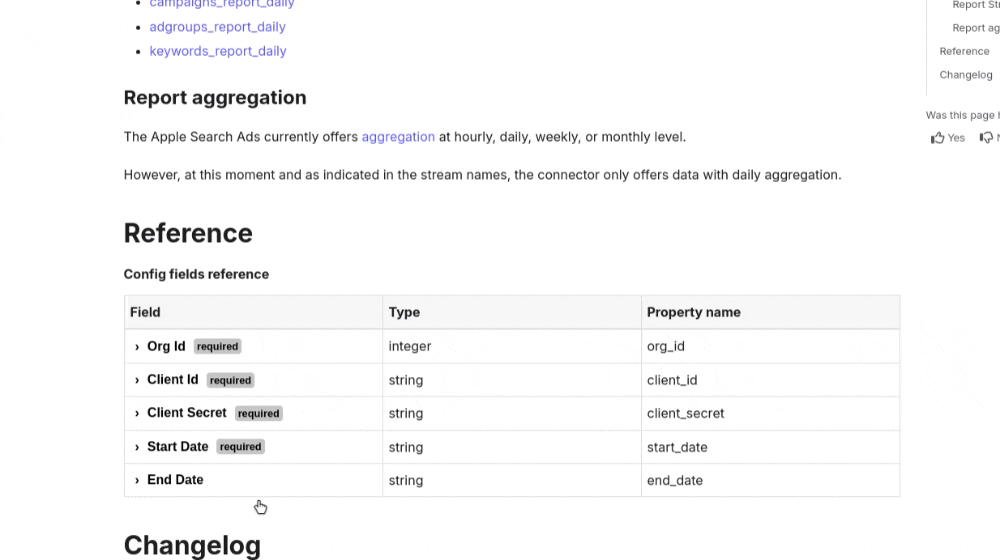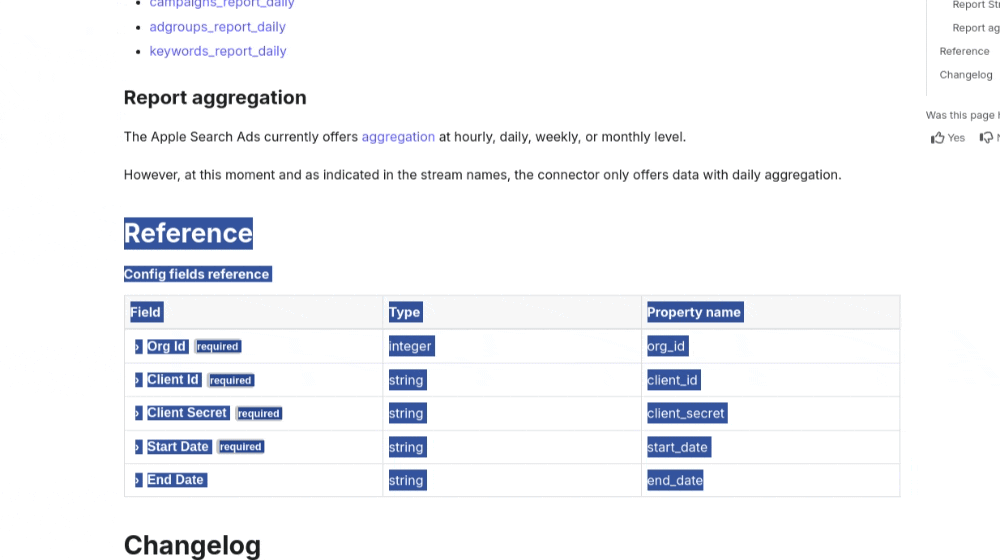
An example of using the linked Airbyte documentation to find form values for Apple Search Ads. You can also use the search functionlity on Airbyte to search using crtl+k or by clicking on the search bar on the top right
Choosing Streams to Sync
Once you input the required form fields, Agent Cloud will test the connection to ensure it is correctly configured and will also prompt you to select thestreams to sync, which essentially is the field(s) of data that are required to synchronise.
An example of the platform prompting to select which fields are to be synchronised, using BigQuery
Sync Mode
The Sync mode is how you wish to synchronise the data. Different sync modes have different effects on how the data is transferred and stored by Agent CloudIncremental Appendsynchronises the data by only getting newely added data.Full Refresh Appendsynchornises the entire datasource to synchronisePlease note that this kind of synchronising can incur costs from the datasource provider and may take longer
Primary Key
The Primary key is the data that will be used by agents within the retrieval process, select the data that you wish to have accessed by the agents (this may be a product description, a product name etc). This will be one of the fields within your datasource.Cursor Field
The cursor field is the field that will be used as the reference for embedding the data. This should be a unique field such asdate created or object ID to ensure that the data is uniuely stored within the vector database. Knowledge of the funcitonality of vector databases is not required for use of Agent Cloud but if you would like to understand the cursor field further, see the Qdrnt docs here
Description
This is simply an arbitrary description of the field, this isn’t used by the agents and isn’t accessed, it’s simply used as a descriptor for the user.Configure Chunking & Embedding
Once the datasource has been connnected and the streams to sync are configured, the embedding and chunking must be configured. Simply put, this covers the embedding process for the data and the type of retrieval to use.Field to Embed
This field is simply the data you wish to have the agents access, this will embed the field and put it into the vector databse for the agents to be able to access. Select the field that you wish to have acessed by the agent(s).Embedding Model
The process of embedding is usually done by an LLM, it is best to already have embedding models configured before starting this step of the setup but you are able to configure on within the popup by selecting the ”+ Create New Model” dropdown option.If you wish you quickly continue with setup without configuring an api key for an external vendor of an LLM you can use FastEmbed.
Please note: FastEmbed is not as intelligent as other models, it allows for easy setup but may not be as efficient, accurate or intelligent as other models. We strongly reccomend changing this later
Retrieval Strategy
The retrieval strategy is the strategy used by Agents to query the embedded data within the vector database.Different retrieval strategies have high impacts on the type of data retrieved by the agents.
Self Query
Self Query
Self query is the process of letting the LLM generate a datasource query from the user’s input prompt. This type of retrieval is particularly useful when there is a large variety of data to be queried.
In essence, this allows for dynamic retrieval of data when different data can represent different things.
Learn more about self-query
In essence, this allows for dynamic retrieval of data when different data can represent different things.
e.g. If you are creating a ‘CEO Chatbot” that can query revenue data, marketing analytics data, engineering analytics data etc… Then this is retrieval strategy will be useful in gathering relevant data based on the query.Example Query: How to get the most out of Self Query.In the above example, self query will generate filtering tags based on the “sale price than $500” to filter retrieval for sales data and the price of a sale. It will also generate relevant tags for “sale date after 1/1/2024” to filter sale dates with the sales data. This achieves more accurate results from the wide range of data.
Find all sales data where the sale is of a higher sale price than$500and the sale date is after1/1/2024
Since the LLM will recursively generate a query based on it’s own outputs this retrieval strategy will have higher token usage than other strategies.
Raw Similarity Search
Raw Similarity Search
Raw simililarity search simply embedds the user’s query and finds similar objects in the vector database. This type of retrieval is more deterministic as it will simply find the most similar results for the given query but it may not work as efficiently when trying to filter data (i.e. “sales data over $x”).
This is particularly useful when using the datasource for retrieval of highly specific data or when token usage must be kept low as this uses significantly less tokens than self query.
This is particularly useful when using the datasource for retrieval of highly specific data or when token usage must be kept low as this uses significantly less tokens than self query.
Multi Query
Multi Query
Multi query is an evolution of the Raw Similarity Search retrieval. Multi Query will use the LLM to generate multiple queries based on the user’s input query.
CONTEXT: Datasource contains end-user “get started” and “setup” documentation for a mobile app.It will then do a raw similarity search on each one of these queries to gather all relevant results. Once a list of relevant results has been gathered it will return the top k results from all of these results.This is a solution that can have more accuracy in returned results than Raw Similarity Search but has less token usage than Self Query, it serves as a middle ground between the two.
user: How can I set up the mobile app
Multi Query: 1. What part of the documentation must I read to understand the setup of the mobile app | 2. How can I find out how to set up the mobile app | etc…
Top K Results
The top k results is the number of results to return to the chat app. If you would like this datasource to return a large amount of data then set this number higher.Schedule Type
The synchronisation of data can happen on a manual or scheduled basis.- Manual requires you to click a button to update it whenever you choose.
- Scheduled gives you the option to synchronise the datasource with Agent Cloud on an hourly, daily, weekly or monthly basis
Please note that frequent synchornises may incur provider costs with your datasource provider